算法总结 DAY_01 两数之和 LeetCode 1. Two Sum
题目: 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,你不能重复利用这个数组中同样的元素。
示例:
题解 暴力法 两层循环遍历:时间复杂度为 O(N^2),空间复杂度为 O(1),运行速度慢且内存空间消耗大。
class Solution {public : vector<int > twoSum (vector<int >& nums, int target) { int size = nums.size (); if (size > 2 ){ sort (nums); for (int i = 0 ; i < size; i++){ for (int j = i+1 ; j < size; j++){ if (target == nums[i] + nums[j]) return {i, j}; } } } return {0 , 1 }; } };
排序法 先排序,快排 O(NlogN)
头尾指针向内移动,相加查找,找到后,原数组遍历定位下标 O(N)
哈希表 对于单个未知数x,利用哈希表寻找target-x的时间复杂度可以降为O(1),对于含有N个数的数组,整个算法的时间复杂度为O(N);由于存储哈希表,空间复杂度为O(N)。代码如下:
class Solution {public : vector<int > twoSum (vector<int >& nums, int target) { unordered_map<int ,int >hashtable; for (int i = 0 ;i < nums.size ();++i) { auto it = hashtable.find (target - nums[i]); if (it != hashtable.end ()) return {it->second,i}; hashtable[nums[i]] = i; } return {}; } };
知识点拓展 vector的概念与性质 vector是顺序容器,本质是动态数组。创建vector容器时需要说明该容器内元素的类型。如下:
vector容器在做形参传递时,可以采用以下三种方式:
void init_vector1 (vector<int >vectest) void init_vector2 (vector<int >&vectest) void init_vector3 (vector<int >*vectest)
init_vector1中是值传递,形参的改变不会对实参有影响,并且会调用vector的拷贝构造函数将实参的值复制给形参。
init_vector2和init_vector3分别是引用传递和指针传递,它们会对实参做出影响。
建议在实际应用中采用引用传递,如下文所示。
vector<int > twoSum (vector<int >& nums, int target) ;
i++和++i的区别 1、赋值顺序不同
i++先赋值后运算,++i先运算后赋值。
2、效率不同
++i的效率比i++高。因为i++先赋值后运算,因此要多生成一个局部对象。如下所示。
CDemo CDemo::operator ++ () { ++n; return *this ; } CDemo CDemo::operator ++(int k) { CDemo tmp (*this ) ; n++; return tmp; }
3、i++无法做左值,++i可以
左值是对应内存中有确定存储地址的对象的表达式的值,而右值是所有不是左值的表达式的值。一般来说,左值是可以放到赋值符号左边的变量。
但能否被赋值不是区分左值与右值的依据。比如,C++的const左值是不可赋值的;而作为临时对象的右值可能允许被赋值。左值与右值的根本区别在于是否允许取地址&运算符获得对应的内存地址。
哈希表 哈希表是一个采用键值和值相互对应的函数,在c++中,与哈希表对应的容器是unordered_map(无序容器)。因此采用unordered_map建立哈希表。
unordered_map<int ,int >hashtable;
该句建立一个名为hashtable的,键值对为<int,int>类型的unordered_map容器。其中<int,int>是指键值对类型,前者是键的类型,后者是值的类型。
auto it = hashtable.find (target - nums[i]);
find(key)是unordered_map容器中寻找键key对应的值的成员方法。若键key与其值的键值对在容器中存在,则返回一个指向该键值对的正向迭代器,反之则返回一个指向容器中最后一个键值对之后位置的迭代器。
if (it != hashtable.end ())
该句判断是否存在我们需要的键值对。成员方法end()生成指向容器中最后一个键值对之后位置的迭代器。
auto标识符 1、auto就是根据变量值推断变量类型。
迭代器iterator的概念与性质 访问、读写容器中的元素,需要使用迭代器iterator。容器可以看作为吉他,迭代器可以看作为拨片,吉他(容器)是声音(元素)的载体,但是使吉他发出声音(能够访问到容器的元素)需要使用拨片(迭代器)。
迭代器根据访问方式分为正向迭代器、双向迭代器、随机访问迭代器。不同的访问方式使得迭代器可以做的运算不同。
迭代器常用功能:::iterator 迭代器名;
2、取得迭代器所指元素
3、移动迭代器,访问下一个元素(移动方法视迭代器类别变化)
在unordered_map容器中,迭代器指向键值对,即指向两个元素,键和值。因此通过迭代器访问unordered_map容器时,需要说明访问的是哪个元素。其中first是键,second是值。
上句即为访问键值对中的值。https://blog.csdn.net/qq_44106937/article/details/116146592
map 与 unordered_map map优点 :有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作。红黑树,内部实现一个红黑书使得map的很多操作在lgn的时间复杂度下就可以实现,因此效率非常的高。缺点 :空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点,孩子节点以及红/黑性质,使得每一个节点都占用大量的空间适用处 :对于那些有顺序要求的问题,用map会更高效一些。
unordered_map优点 :内部实现了哈希表,因此其查找速度是常量级别的。缺点 :哈希表的建立比较耗费时间适用处 :对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map
使用方法:
map
#include <iostream> #include <map> #include <string> using namespace std; int main () map<string, int > dict; dict.insert (pair<string,int >("apple" ,2 )); dict.insert (map<string, int >::value_type ("orange" ,3 )); dict["banana" ] = 6 ; if (dict.empty ()) cout<<"该字典无元素" <<endl; else cout<<"该字典共有" <<dict.size ()<<"个元素" <<endl; map<string, int >::iterator iter; for (iter=dict.begin ();iter!=dict.end ();iter++) cout<<iter->first<<ends<<iter->second<<endl; if ((iter=dict.find ("banana" ))!=dict.end ()) cout<<"已找到banana,其value为" <<iter->second<<"." <<endl; else cout<<"未找到banana." <<endl; if (dict.count ("watermelon" )==0 ) cout<<"watermelon不存在" <<endl; else cout<<"watermelon存在" <<endl; pair<map<string, int >::iterator, map<string, int >::iterator> ret; ret = dict.equal_range ("banana" ); cout<<ret.first->first<<ends<<ret.first->second<<endl; cout<<ret.second->first<<ends<<ret.second->second<<endl; iter = dict.lower_bound ("boluo" ); cout<<iter->first<<endl; iter = dict.upper_bound ("boluo" ); cout<<iter->first<<endl; return 0 ; }
unordered_map
#include <string> #include <iostream> #include <unordered_map> using namespace std; int main () unordered_map<string, int > dict; dict.insert (pair<string,int >("apple" ,2 )); dict.insert (unordered_map<string, int >::value_type ("orange" ,3 )); dict["banana" ] = 6 ; if (dict.empty ()) cout<<"该字典无元素" <<endl; else cout<<"该字典共有" <<dict.size ()<<"个元素" <<endl; unordered_map<string, int >::iterator iter; for (iter=dict.begin ();iter!=dict.end ();iter++) cout<<iter->first<<ends<<iter->second<<endl; if (dict.count ("boluo" )==0 ) cout<<"can't find boluo!" <<endl; else cout<<"find boluo!" <<endl; if ((iter=dict.find ("banana" ))!=dict.end ()) cout<<"banana=" <<iter->second<<endl; else cout<<"can't find boluo!" <<endl; return 0 ; }
参考链接:https://blog.csdn.net/zou_albert/article/details/106983268
重复的DNA序列 LeetCode 187. Repeated DNA Sequences
题目: DNA序列 由一系列核苷酸组成,缩写为 ‘A’, ‘C’, ‘G’ 和 ‘T’.。
例如,”ACGAATTCCG” 是一个 DNA序列 。
给定一个表示 DNA序列 的字符串 s ,返回所有在 DNA 分子中出现不止一次的 长度为 10 的序列(子字符串)。你可以按 任意顺序 返回答案。
示例 1:
输入:s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT" 输出:["AAAAACCCCC","CCCCCAAAAA"]
示例 2:
输入:s = "AAAAAAAAAAAAA" 输出:["AAAAAAAAAA"]
提示:
0 <= s.length <= 105 s[i]=='A'、'C'、'G' or 'T'
题解 哈希表
class Solution {public : int L = 10 ; vector<string> findRepeatedDnaSequences (string s) { vector<string> ans; unordered_map<string,int > map; if (s.length () > L) for (int i=0 ; i <= s.length () - L; i++){ string temp = s.substr (i, L); if (++map[temp] == 2 ) ans.push_back (temp); } return ans; ans.push_back (s); return ans; } };
哈希表 + 滑动窗口 + 位运算
时间复杂度:O(N),其中 N 是字符串 s 的长度。
空间复杂度:O(N)。
由于 s 中只含有 4 种字符,我们可以将每个字符用 2 个比特表示,即:
A 表示为二进制 00; C 表示为二进制 01; G 表示为二进制 10; T 表示为二进制 11。
如此一来,一个长为 10 的字符串就可以用 20 个比特表示,而一个 int 整数有 32 个比特,足够容纳该字符串,因此我们可以将 s 的每个长为 10 的子串用一个 int 整数表示(只用低 20 位)。
注意到上述字符串到整数的映射是一一映射,每个整数都对应着一个唯一的字符串,因此我们可以将方法一中的哈希表改为存储每个长为 10 的子串的整数表示。
如果我们对每个长为 10 的子串都单独计算其整数表示,那么时间复杂度仍然和方法一一样为 O(NL)。为了优化时间复杂度,我们可以用一个大小固定为 10 的滑动窗口来计算子串的整数表示。设当前滑动窗口对应的整数表示为 x,当我们要计算下一个子串时,就将滑动窗口向右移动一位,此时会有一个新的字符进入窗口,以及窗口最左边的字符离开窗口,这些操作对应的位运算,按计算顺序表示如下:
滑动窗口向右移动一位:x = x << 2,由于每个字符用 2 个比特表示,所以要左移 2 位;x = x | bin[ch],这里 bin[ch] 为字符 ch 的对应二进制;O(1) 的时间计算出下一个子串的整数表示,即 x = ((x << 2) | bin[ch]) & ((1 << 20) - 1)。
class Solution { const int L = 10 ; unordered_map<char , int > bin = {{'A' , 0 }, {'C' , 1 }, {'G' , 2 }, {'T' , 3 }}; public : vector<string> findRepeatedDnaSequences (string s) { vector<string> ans; int n = s.length (); if (n <= L) { return ans; } int x = 0 ; for (int i = 0 ; i < L - 1 ; ++i) { x = (x << 2 ) | bin[s[i]]; } unordered_map<int , int > cnt; for (int i = 0 ; i <= n - L; ++i) { x = ((x << 2 ) | bin[s[i + L - 1 ]]) & ((1 << (L * 2 )) - 1 ); if (++cnt[x] == 2 ) { ans.push_back (s.substr (i, L)); } } return ans; } };
知识点拓展 substr()函数用法 substr (size_type _Off = 0 ,size_type _Count = npos)
一种构造string的方法形式 : s.substr(pos, len)返回值 : string,包含s中从pos开始的len个字符的拷贝(pos的默认值是0,len的默认值是s.size() - pos,即不加参数会默认拷贝整个s)异常 :若pos的值超过了string的大小,则substr函数会抛出一个out_of_range异常;若pos+n的值超过了string的大小,则substr会调整n的值,只拷贝到string的末尾
参考链接:https://blog.csdn.net/weixin_42240667/article/details/103131329
C++_vector操作 vector 说明 :
vector是向量类型,可以容纳许多类型的数据,因此也被称为容器
(可以理解为动态数组,是封装好了的类)
进行vector操作前应添加头文件#include <vector>
vector初始化 :
vector<int >a (10 ); vector<int >a (10 ,1 ); vector<int >a (b); vector<int >a (b.begin (),b.begin+3 ); int b[7 ]={1 ,2 ,3 ,4 ,5 ,6 ,7 };vector<int > a (b,b+7 );
vector对象的常用内置函数使用(举例说明)
#include <vector> vector<int > a,b; a.assign (b.begin (),b.begin ()+3 ); a.assign (4 ,2 ); a.back (); a.front (); a[i]; a.clear (); a.empty (); a.pop_back (); a.erase (a.begin ()+1 ,a.begin ()+3 ); a.push_back (5 ); a.insert (a.begin ()+1 ,5 ); a.insert (a.begin ()+1 ,3 ,5 ); a.insert (a.begin ()+1 ,b+3 ,b+6 ); a.size (); a.capacity (); a.resize (10 ); a.resize (10 ,2 ); a.reserve (100 ); a.swap (b); a==b;
对向量a添加元素的几种方式
vector<int >a; for (int i=0 ;i<10 ;++i){a.push_back (i);}int a[6 ]={1 ,2 ,3 ,4 ,5 ,6 };vector<int > b; for (int i=0 ;i<=4 ;++i){b.push_back (a[i]);}int a[6 ]={1 ,2 ,3 ,4 ,5 ,6 };vector<int >b; vector<int >c (a,a+4 ); for (vector<int >::iterator it=c.begin ();it<c.end ();++it){ b.push_back (*it); } ifstream in ("data.txt" ) ;vector<int >a; for (int i;in>>i){a.push_back (i);}vector<int >a; for (int i=0 ;i<10 ;++i){a[i]=i;}
从向量中读取元素
int a[6 ]={1 ,2 ,3 ,4 ,5 ,6 };vector<int >b (a,a+4 ); for (int i=0 ;i<=b.size ()-1 ;++i){cout<<b[i]<<endl;} int a[6 ]={1 ,2 ,3 ,4 ,5 ,6 }; vector<int >b (a,a+4 ); for (vector<int >::iterator it=b.begin ();it!=b.end ();it++){cout<<*it<<" " ;}
几个常用的算法
#include <algorithm> sort (a.begin (),a.end ()); reverse (a.begin (),a.end ()); copy (a.begin (),a.end (),b.begin ()+1 ); find (a.begin (),a.end (),10 );
参考链接:https://blog.csdn.net/weixin_41743247/article/details/90635931
设置哈希映射 LeetCode 706. Design HashMap
题目: 不使用任何内建的哈希表库设计一个哈希映射(HashMap)。
实现 MyHashMap 类:
MyHashMap() 用空映射初始化对象
void put(int key, int value) 向 HashMap 插入一个键值对 (key, value) 。如果 key 已经存在于映射中,则更新其对应的值 value 。
int get(int key) 返回特定的 key 所映射的 value ;如果映射中不包含 key 的映射,返回 -1 。
void remove(key) 如果映射中存在 key 的映射,则移除 key 和它所对应的 value 。
示例:
输入: ["MyHashMap", "put", "put", "get", "get", "put", "get", "remove", "get"] [[], [1, 1], [2, 2], [1], [3], [2, 1], [2], [2], [2]] 输出: [null, null, null, 1, -1, null, 1, null, -1] 解释: MyHashMap myHashMap = new MyHashMap(); myHashMap.put(1, 1); // myHashMap 现在为 [[1,1]] myHashMap.put(2, 2); // myHashMap 现在为 [[1,1], [2,2]] myHashMap.get(1); // 返回 1 ,myHashMap 现在为 [[1,1], [2,2]] myHashMap.get(3); // 返回 -1(未找到),myHashMap 现在为 [[1,1], [2,2]] myHashMap.put(2, 1); // myHashMap 现在为 [[1,1], [2,1]](更新已有的值) myHashMap.get(2); // 返回 1 ,myHashMap 现在为 [[1,1], [2,1]] myHashMap.remove(2); // 删除键为 2 的数据,myHashMap 现在为 [[1,1]] myHashMap.get(2); // 返回 -1(未找到),myHashMap 现在为 [[1,1]]
提示:
0 <= key, value <= 106 最多调用 104 次 put、get 和 remove 方法
题解 暴力一维数组 class MyHashMap {public : MyHashMap () { m = vector<int > (1000001 , -1 ); } void put (int key, int value) m[key] = value; } int get (int key) return m[key]; } void remove (int key) m[key] = -1 ; } private : vector<int > m; };
链地址法 我们假定读者已经完成了705. 设计哈希集合 这一题目。
设哈希表的大小为 base,则可以设计一个简单的哈希函数:x mod base。
我们开辟一个大小为 base 的数组,数组的每个位置是一个链表。当计算出哈希值之后,就插入到对应位置的链表当中。
由于我们使用整数除法作为哈希函数,为了尽可能避免冲突,应当将base 取为一个质数。在这里,我们取 =769。
「设计哈希映射」与「设计哈希集合」解法接近,唯一的区别在于我们存储的不是 key 本身,而是 (key,value) 对。除此之外,代码基本是类似的。
class MyHashMap {private : vector<list<pair<int , int >>> data; static const int base = 769 ; static int hash (int key) return key % base; } public : MyHashMap (): data (base) {} void put (int key, int value) int h = hash (key); for (auto it = data[h].begin (); it != data[h].end (); it++) { if ((*it).first == key) { (*it).second = value; return ; } } data[h].push_back (make_pair (key, value)); } int get (int key) int h = hash (key); for (auto it = data[h].begin (); it != data[h].end (); it++) { if ((*it).first == key) { return (*it).second; } } return -1 ; } void remove (int key) int h = hash (key); for (auto it = data[h].begin (); it != data[h].end (); it++) { if ((*it).first == key) { data[h].erase (it); return ; } } } };
复杂度分析
知识点拓展 pair 结合 vector用法 pair:一对值可以具有不同的数据类型
pair<string , int > p; make_pair (x,y)
定义使用pair的vector:
vector<pair<string,int >>vec; 定义使用pair的vector: vec.push_back (make_pair (x,y)); vec[i].first vec[i].second
结合sort函数
static bool cmp (pair<string,int >&a,pair<string,int >&b) if (a.second == b.second) { return a.first < b.first; } return a.second > b.second; } sort (vec.begin (),vec.end (),cmp);
结合map,vector和pair
for (it = map.begin ();it!=map.end ();++it){ temp.push_back (make_pair (it->first,it->second)); }
平分数组 题目: 一个整数数组a,长度为n,将其分为m份,使各份的和相等,求m的最大值
示例1:
{3,2,4,3,6} 可以分成{3,2,4,3,6} m=1; {3,6}{2,4,3} m=2 {3,3}{2,4}{6} m=3 所以m的最大值为3
题解 递归 思路和算法
求出数组和 SUM。
假设可以分成m组,找到一个合适的m. m的取值为sum%m=0,m<=sum/max(a[i])
从大到小验证找到一个可行的m值. 此过程可以用递归。f(a,m)=f(a-set,m-1)
int maxShares (int a[], int n) int sum = 0 ; int i, m; for (i=0 ; i<n; i++) sum += a[i]; for (m=n; m>=2 ; m--) { if (sum mod m != 0 ) continue ; int aux[n]; for (i=0 ; i<n; i++) aux[i] = 0 ; if (testShares (a, n, m, sum, sum/m, aux, sum/m, 1 )) return m; } return 1 ; } int testShares (int a[], int n, int m, int sum, int groupsum, int [] aux, int goal, int groupId) if (goal == 0 ) { groupId++; if (groupId == m+1 ) return 1 ; } for (int i=0 ; i<n; i++) { if (aux[i] != 0 ) continue ; aux[i] = groupId; if (testShares (a, n, m, sum, groupsum, aux, goal-a[i], groupId)) { return 1 ; } aux[i] = 0 ; } }
参考链接:https://www.cnblogs.com/catkins/archive/2012/11/16/5270694.html
和为 K 的子数组 LeetCode 560. Subarray Sum Equals K
题目: 给你一个整数数组 nums 和一个整数 k ,请你统计并返回该数组中和为 k 的连续子数组的个数。
示例 1:
输入:nums = [1,1,1], k = 2 输出:2
示例 2:
输入:nums = [1,2,3], k = 3 输出:2
提示:
1 <= nums.length <= 2 * 104 -1000 <= nums[i] <= 1000 -107 <= k <= 107
题解 枚举 思路和算法
考虑以 i 结尾和为 k 的连续子数组个数,我们需要统计符合条件的下标 j 的个数,其中0≤j≤i 且 [j..i] 这个子数组的和恰好为 k 。
我们可以枚举 [0..i] 里所有的下标 j 来判断是否符合条件,可能有读者会认为假定我们确定了子数组的开头和结尾,还需要 O(n) 的时间复杂度遍历子数组来求和,那样复杂度就将达到 O(n^3) 从而无法通过所有测试用例。但是如果我们知道 [j,i] 子数组的和,就能 O(1) 推出 [j-1,i] 的和,因此这部分的遍历求和是不需要的,我们在枚举下标 j 的时候已经能 O(1) 求出 [j,i] 的子数组之和。
class Solution {public : int subarraySum (vector<int >& nums, int k) int count = 0 ; for (int start = 0 ; start < nums.size (); ++start) { int sum = 0 ; for (int end = start; end >= 0 ; --end) { sum += nums[end]; if (sum == k) { count++; } } } return count; } };
复杂度分析
前缀和 + 哈希表优化 思路和算法
将前缀和pre存入哈希表,出现相同的key值value加一,使用两数之和的方式寻找。
class Solution {public : int subarraySum (vector<int >& nums, int k) unordered_map<int , int > map; vector<int > anum; int Count = 0 ; anum.push_back (0 ); for (int i=0 ; i<nums.size (); i++){ anum.push_back (nums[i]+anum[i]); } for (int i=0 ; i<nums.size ()+1 ; i++){ auto it = map.find (anum[i] - k); if (it != map.end ()) Count += map[anum[i] - k]; map[anum[i]] ++; } return Count; } };
官方题解:
class Solution {public : int subarraySum (vector<int >& nums, int k) unordered_map<int , int > mp; mp[0 ] = 1 ; int count = 0 , pre = 0 ; for (auto & x:nums) { pre += x; if (mp.find (pre - k) != mp.end ()) { count += mp[pre - k]; } mp[pre]++; } return count; } };
复杂度分析
知识点拓展 (auto& x:nums)用法 b为数组 或容器,是被遍历的对象
for(auto &a:b),for(auto &&a:b),循环体中修改a,b中对应内容也会修改(&& 右值引用,不用复制拷贝,速度更快)
for(auto a:b),循环体中修改a,b中内容不受影响
for(const auto &a:b),a不可修改,用于只读取b中内容
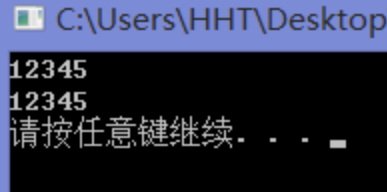
#include <iostream> using namespace std;void main () int arr[5 ] = {1 ,2 ,3 ,4 ,5 }; for (auto &a : arr){ cout << a; } cout << endl; for (auto a : arr){ cout << a; } cout << endl; system ("pause" ); }
如果仅仅对b进行读取操作,而不修改,两者效果一致,如下:
如果需要对b进行修改,则需要用for(auto &a:b),如下:
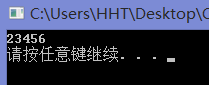
#include <iostream> using namespace std;void main () int arr[5 ] = {1 ,2 ,3 ,4 ,5 }; for (auto &a : arr){ a++; } for (auto a : arr){ cout << a; } cout << endl; system ("pause" ); }
如果不加&符号,则b不会发生任何修改。


 微信
微信 支付宝
支付宝









