
爬取Bilibili排行榜
爬取哔哩哔哩排行榜信息
前言
这是作者的一个Python通选课的小项目(有些粗糙)
本项目参考自:三秋树&二月花
原项目爬取时间为2020.12,B站排行榜源码已发生改变,目前已无法爬取。
本项目爬取时间为2021.12
项目源码: https://github.com/chenduowen233/Py-Bilibili
通过爬取哔哩哔哩排行榜,支持获取并分析番剧、国产动画、纪录片、电视剧等排行榜的排名、更新话数、播放量、平均每话播放量、追番人数等数据,并绘制出可视化视图。
数据爬取
爬取网页网址:
# 国产动画排行榜分析 |
使用requests.get来获取网页数据:
requests.get(url) |
数据清洗
构建BeautifulSoup实例
解析网页 指定BeautifulSoup的解析器:
soup = BeautifulSoup(html, 'html.parser') |
初始化要存入信息的容器
name = [] # 动漫名字 |
数据解析与提取
使用beautifulsoup的find_all() 解析数据
find_all()的第一个参数是标签名,第二个是标签中的class值

使用正则表达式提取所需数据
import re |
提取剧名:
for tag in soup.find_all('div', class_='info'): |
提取更新话数:
for tag in soup.find_all('div', class_='detail'): |
提取播放量:
for tag in soup.find_all('div', class_='detail-state'): |
提取追番人数:
for tag in soup.find_all('div', class_='detail-state'): |
.next_sibling是用于提取同级别的相同标签信息
数据分析与统计
引入numpy:
由多维数组对象和用于处理数组的例程集合组成的库
import numpy as np |
利用 np.divide 将数组对应相除求出平均每话的播放量:
pjbfl = np.divide(bfl, hua) |
文件存储
存储方式:.txt:

将解析后的数据存入文本文件:
with open('./data/B_data.txt', 'r+', encoding='UTF-8') as f: |
解析后的数据: 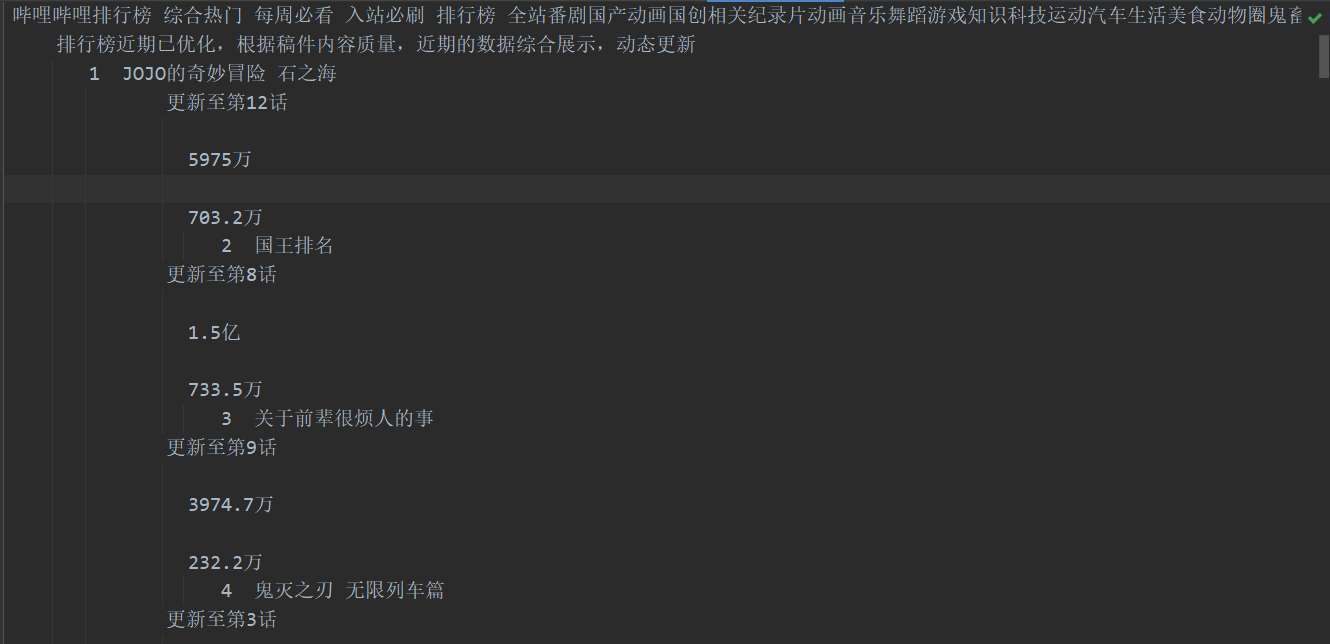
存储方式:.xlsx:

将提取后的数据存入Bilibili.xlsx文件:
dm_file = pandas.DataFrame(info) |
番剧排行榜:

电视剧排行榜:
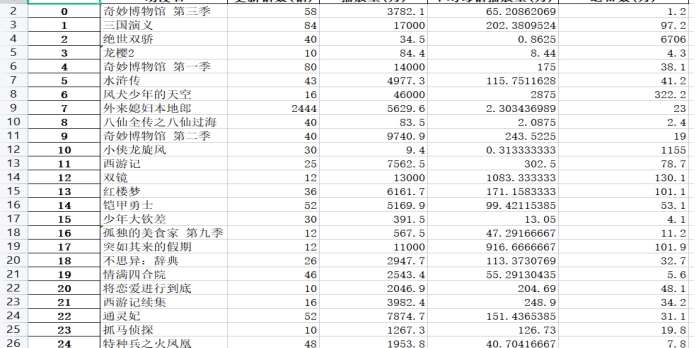
数据可视化
采用Matplotlib进行可视化
Matplotlib是一个在 python 下实现的类 matlab 的纯 python 的第三方库。
绘图示例: https://matplotlib.org/stable/gallery/index
PDF版本示例: https://github.com/matplotlib/cheatsheets
设置中文字体:
my_font = font_manager.FontProperties(fname='./data/STHeiti Medium.ttc') |
绘制图形,实现数据可视化分析:
fig, ax1 = plt.subplots() |
具体绘制实现五种数据可视化分析图:
播放量数据分析:
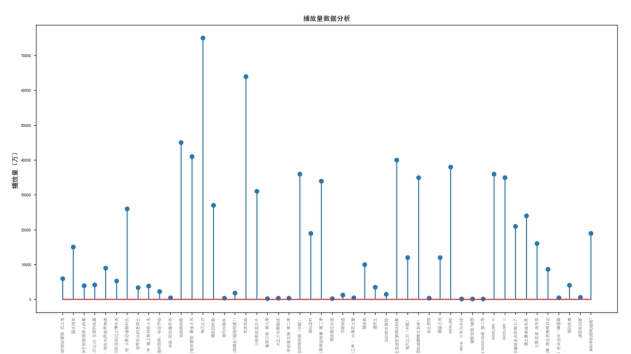
更新话数和播放量数据分析:

平均每话播放量数据分析:

平均每话播放量数和播放量数分析:
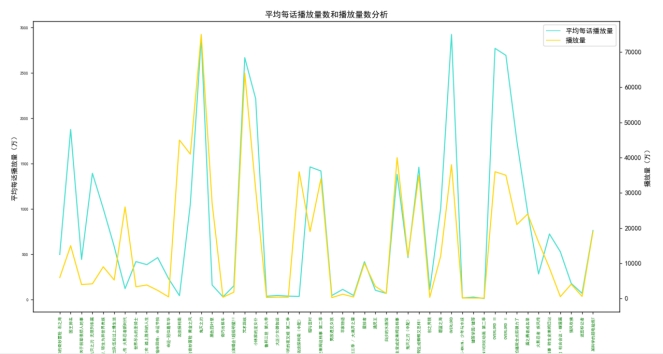
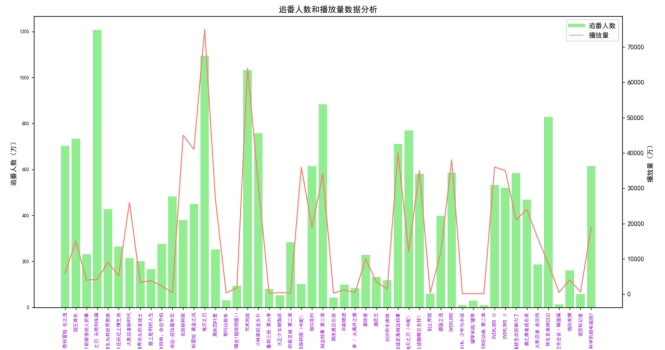
追番人数和播放量数据分析:
 微信
微信 支付宝
支付宝




